Reverse engineering the Adreno Vulkan driver
Being an engine programmer usually means being a bit of a jack of all trades. There’s always something weird going on and you have to be pretty familiar with a bunch of low level details that come in handy in unexpected ways. Recently I went down a somewhat unexpected rabbit hole where those skills came in extremely hand. In an effort to blog more and also because it seems like I was the first to run into this issue, I figured I should sit down and just write about it so future people can benefit from it.
We are currently working on porting the engine of X-Plane mobile from GLES to Vulkan. On Desktop we did the transition to Vulkan 4 years ago already, but mobile was always a harder target because the driver quality is just so much worse and updates to them are almost non-existent. But time marches forward and so, at long last, we are bringing Vulkan to X-Plane mobile in a project dubbed Vandroid. One issue we ran into was that calling vkEndCommandBuffer() would segfault on Adreno devices. In particular, it would segfault on a Samsung A52 with Adreno 530 running the latest version of Android. The backtrace looks like this:
(lldb) bt
* thread #41, name = 'Thread-8', stop reason = breakpoint 31.1
* frame #0: 0x000000708cfc3fd8 libart.so`art_sigsegv_fault
frame #1: 0x000000708cfc456c libart.so`art::FaultManager::HandleSigsegvFault(int, siginfo*, void*) + 1096
frame #2: 0x000000733e77506c libsigchain.so`art::SignalChain::Handler(int, siginfo*, void*) + 372
frame #3: 0x0000007352f6b60c [vdso]`__kernel_rt_sigreturn
frame #4: 0x0000006fdf6b7cc4 vulkan.adreno.so`!!!0000!2b721a8d8a3fb4c38f1424ebe303ae!cc892008d2! + 116
frame #5: 0x0000006fdf6b9968 vulkan.adreno.so`!!!0000!14b6c2f93eb6db0e6f18291e76a639!cc892008d2! + 648
frame #6: 0x0000006fdf6aa3a4 vulkan.adreno.so`!!!0000!0cbc7822fa6fed1df7f71350d1e2a2!cc892008d2! + 6068
frame #7: 0x0000006fdf6dd6f0 vulkan.adreno.so`!!!0000!eb5b505d69e1d6fb17275ef337cfa2!cc892008d2! + 928
frame #8: 0x0000006fdf68858c vulkan.adreno.so`qglinternal::vkEndCommandBuffer(VkCommandBuffer_T*) + 396
frame #9: 0x0000006fedb9d8ac libXPlane10.so`gfx_vk_command_buffer::__end_command_buffer(this=0xb40000727f27b6f0, needs_transfer=<unavailable>) at gfx_vk_command_buffer.cpp:192:2
frame #10: 0x0000006fedb9ddec libXPlane10.so`gfx_vk_command_buffer::end_with_transfer_flush(this=0xb40000727f27b6f0, needs_transfer=<unavailable>) at gfx_vk_command_buffer.cpp:229:2
frame #11: 0x0000006fed3419e0 libXPlane10.so`wmgr_window_present(win=0xb40000725f20ea10) at window_mgr.cpp:3053:19
// ... snip
The validation layers were happy and this code has been running in production on desktop environments for years. Being the resident Vulkanologist, this issue ended up on my plate. One of the first things I like to do with issues in existing code bases that suddenly fall apart, is to just reduce everything to the bare minimum. X-Planes Vulkan backend makes use of various extensions and features for performance reasons. Things like push descriptors, descriptor update templates (I know, very fancy), extended dynamic state, that sort of thing. So the obvious first step was to just disable every single optional feature and extension and falling back to the most basic Vulkan code base. This changed nothing. However, bypassing every draw call allowed me to see the clear colour and it would no longer crash. So, narrowed it down to draw calls. I felt overconfident that this was going to be easy.
And then a whole lot of nothing. I messed around with just about anything that I could think of including moving all rendering offscreen just to see what happens. I tried to narrow it down to a specific draw call, but no matter what, as soon as there was a draw call it would just explode. Validation layers were happy, the Vulkan cube sample worked and googling gave me zero results. Somehow just our engine would crash when ending command buffers that had seen any drawing. Eventually, I did the only logical thing: Fired up Ghidra and loaded up the Adreno driver. I know very little about Android, but I do know Vulkan and C++ and I’m just dangerous enough when it comes to disassembling software.
There are 5 frames in the Adreno driver itself and because Vulkan is a very clearly specified API, I felt like I wasn’t going to just play around with a magic black box. So after letting Ghidra analyze the vulkan.adreno.so file that I had fished out of ADB, I put bookmarks down in the 5 stack frames from the backtrace and started staring at the code for vkEndCommandBuffer(). The first thing the function does is de-reference the VkCommandBuffer_T pointer passed into the function and then do more stuff with that retrieved object. So it seems like the opaque VkCommandBuffer_T is just a wrapper around some internal object that I ended up calling AdrenoCommandBuffer. The AdrenoCommandBuffer object is massive, clocking in at a whopping 2888 bytes, but I figured most members were not super interesting to me.
vkEndCommandBuffer
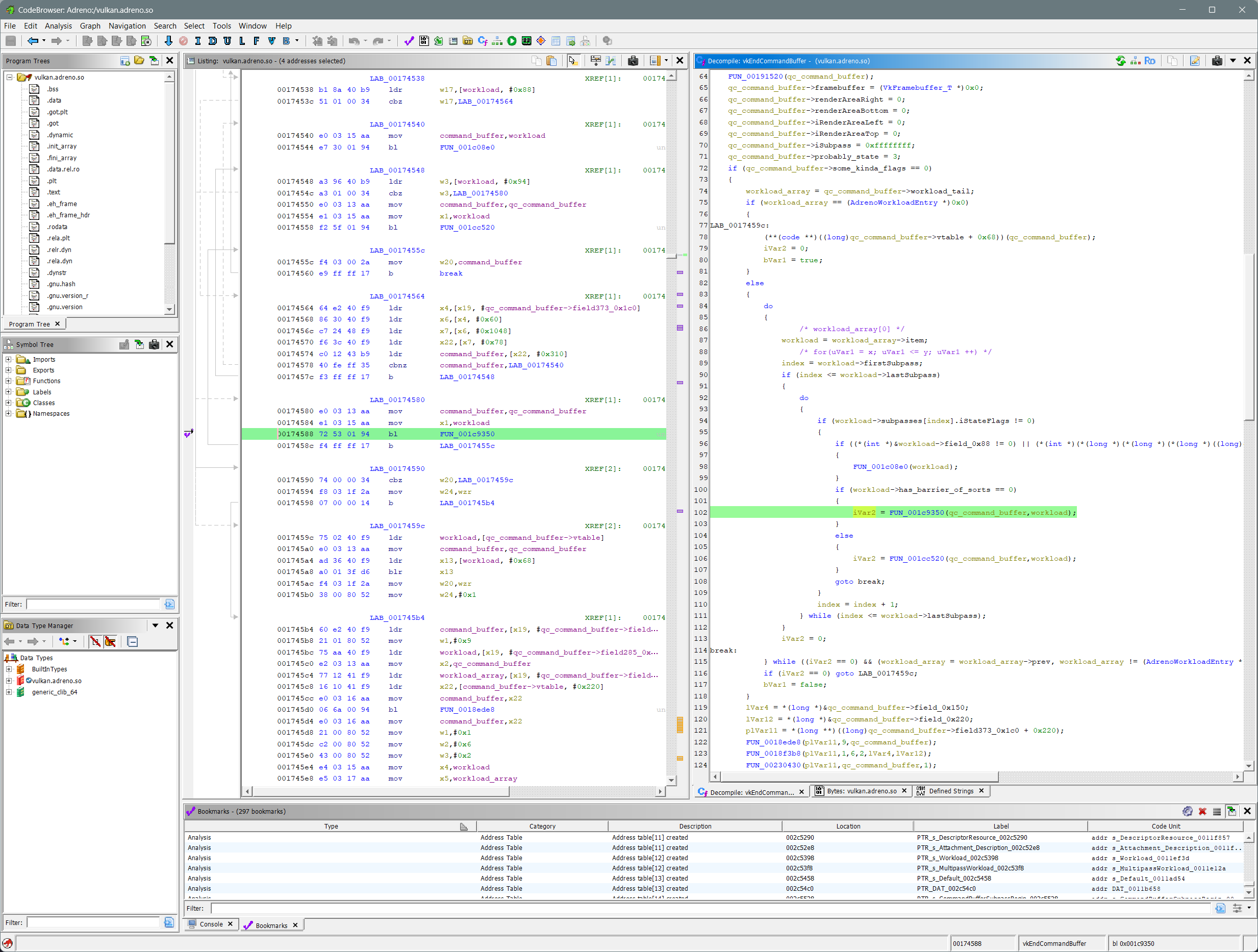
Note: To make this nicer for reading, all code shown is going to be post-mortem with my reverse engineered struct, member and variable names. Also going forward, I will be putting the code into code tags instead of using Ghidra screenshots, just to make things more readable and to not subject you to my terrible font size choices. But just for comparison, this is what this mess looked like originally:
FUN_00191520(plVar9);
plVar9[0x3e] = 0;
*(undefined8 *)((long)plVar9 + 0x20c) = 0;
*(undefined8 *)((long)plVar9 + 0x204) = 0;
plVar9[0x3f] = 0xffffffff;
*(undefined4 *)((long)plVar9 + 0x3fc) = 3;
if (*(int *)(plVar9 + 0x46) == 0)
{
plVar11 = (long *)plVar9[0x78];
if (plVar11 == (long *)0x0)
{
LAB_0017459c:
(**(code **)(*plVar9 + 0x68))(plVar9);
iVar3 = 0;
bVar2 = true;
}
else
{
do
{
lVar10 = *plVar11;
uVar1 = *(uint *)(lVar10 + 0x58);
if (uVar1 <= *(uint *)(lVar10 + 0x5c))
{
do
{
if (*(int *)(*(long *)(lVar10 + 0x78) + (ulong)uVar1 * 0x80) != 0)
{
if ((*(int *)(lVar10 + 0x88) != 0) || (*(int *)(*(long *)(*(long *)(*(long *)(plVar9[0x38] + 0x60) + 0x1048) + 0x78) + 0x310) != 0))
{
FUN_001c08e0(lVar10);
}
if (*(int *)(lVar10 + 0x94) == 0)
{
iVar3 = FUN_001c9350(plVar9,lVar10); // Function call leading to crash
}
else
{
iVar3 = FUN_001cc520(plVar9,lVar10);
}
goto LAB_00174504;
}
uVar1 = uVar1 + 1;
} while (uVar1 <= *(uint *)(lVar10 + 0x5c));
}
iVar3 = 0;
LAB_00174504:
} while ((iVar3 == 0) && (plVar11 = (long *)plVar11[1], plVar11 != (long *)0x0));
if (iVar3 == 0) goto LAB_0017459c;
bVar2 = false;
}
// ...
I took a look at all the other frames as well, but nothing was really jumping out to me. It was clear that the driver was doing some post processing work when ending a command buffer and that it was iterating over some sort of list. The obvious guess is that the list it was iterating over was some sort of command packet structure. My best guess was that, once the command buffer is done getting encoded, the driver would walk over the internal commands and patch up things as needed and then somehow explode while doing so.
My next stop was vkCmdDrawIndexed() because this function was clearly generating some sort of work that would eventually lead to the crash. vkCmdDrawIndexed first sets up a bunch of state on the internal command buffer object, copying a bunch of the function parameters and zeroing out a bunch of other things. However, at the end, there was this code that was a very lucky break:
if ((*(long *)(plVar7[0x38] + 0x218) != 0) && ((DAT_002c5a60 & 1) != 0))
{
FUN_0021ddb0(*(long *)(plVar7[0x38] + 0x218),plVar7,plVar7[0x3a],*(undefined4 *)(plVar7 + 0x3f),lVar3,param_2,*(undefined4 *)(plVar7 + 0x5a),plVar7[0xd],param_3);
}
Following FUN_0021ddb0, it turned out to be a very small function that did a bunch of fwrite() calls. Pay dirt! Turns out this is part of the internal logging functionality of the driver and logging functions are amazing for reverse engineering: The compiler will throw away all nice debug information like struct layouts and member names, but debug loggers tend to write strings together with some values, which can then be used to go back and fill in the blanks. The debug function in question is composed of an inner function that takes, what I think is, a debug tag and an array of strings to form a debug header.
These are the strings passed in:
002b3598 29 f6 11 addr s_DrawElements_0011f629 = "DrawElements"
00 00 00
00 00
002b35a0 75 f3 11 addr s_pCommand_Buffer_0011f375 = "pCommand Buffer"
00 00 00
00 00
002b35a8 4b f8 11 addr s_pRenderPass_0011f84b = "pRenderPass"
00 00 00
00 00
002b35b0 34 e9 11 addr s_iSubpass_0011e934 = "iSubpass"
00 00 00
00 00
002b35b8 29 db 11 addr s_pWorkload_0011db29 = "pWorkload"
00 00 00
00 00
002b35c0 7e ba 11 addr s_iVertex_Count_0011ba7e = "iVertex Count"
00 00 00
00 00
002b35c8 ae a8 11 addr s_iVertex_Type_0011a8ae = "iVertex Type"
00 00 00
00 00
002b35d0 b8 bc 11 addr s_pIndex_Buffer_0011bcb8 = "pIndex Buffer"
00 00 00
00 00
002b35d8 ad cc 11 addr s_iInstance_Count_0011ccad = "iInstance Count"
00 00 00
00 00
And here is the meat of the logging function:
int log_draw_indexed_data(DebugContextThing *param_1,AdrenoCommandBuffer *pCommandBuffer,VkRenderPass_T *pRenderPass,uint32_t iSubpass,void *pWorkload,uint32_t iVertexCount,uint32_t iVertexType,void *pIndexBuffer)
{
// ... Snip
cVar1 = log_debug_tag(param_1,0x10,&PTR_s_DrawElements_002b3598,9);
fputc((int)cVar1,param_1->file);
fwrite(&pCommandBuffer,8,1,param_1->file);
fwrite(&pRenderPass,8,1,param_1->file);
fwrite(&iSubpass,4,1,param_1->file);
fwrite(&pWorkload,8,1,param_1->file);
fwrite(&iVertexCount,4,1,param_1->file);
fwrite(&iVertexType,4,1,param_1->file);
fwrite(&pIndexBuffer,8,1,param_1->file);
fwrite(&stack0x00000000,4,1,param_1->file); // Passed on the stack, but it's the instance count
// ... snip
}
This is cleaned up a bit for brevity, the raw code has more temporaries and guards everything behind a mutex. Interestingly, the debug toy seems to produce binary data instead of text data. All values are written directly into the file, but that actually turned out to be a pretty neat thing because it also told me exactly what size the variables are. There are a lot of very similar functions all following the same structure. Presumably this is all auto generated by some macro or other functionality, which is why very similar functions are all over the place. I’m also guessing a lot of this code is shared from the GLES driver, because the debug strings call this DrawElements which is very much a GL name and not a Vulkan one.
Armed with this and a quick look at the other draw functions, I was able to figure out what vkCmdDrawIndexed() and friends do: The internal command buffer has a struct for the current draw state, this is where the function copies the function parameters into. This object lives inside of the command buffer because it also checks the previous draw state to potentially set some flags. Presumably to make sure caches are flushed, the logic looks something like this:
cb = command_buffer->internal_command_buffer;
pWorkload = retrieve_workload(cb);
draw_state = cb->draw_state;
if ((((draw_state.firstInstance != firstInstance) || (draw_state.vertexOffset != vertexOffset)) ||
(pWorkload->subpasses[cb->iSubpass].iAccumulatedDraws == 0)) || (draw_state.indirectBuffer != (void *)0x0))
{
cb->flags_of_some_kind = cb->flags_of_some_kind | 0x440;
}
It then filled in the draw_state object with 0s and then filled it out with the parameters passed in plus some other data from the command buffer object. This would then end up in some other functions that actually did anything with all of these values.
My attention was on the pWorkload object though. I knew this is what the driver called this object internally from the debug logging function and it was something attached to the command buffer object. It felt like it might just hold some sort of command packet like structure, so I ended up looking at retrieve_workload() first (it goes without saying, but that’s what I ended up calling this function, not what Qualcomm calls it). Also, if you looked at the Ghidra screenshot earlier, you will have the luxury of hindsight and having seen that the workload will indeed be relevant. Not having the luxury of hindsight when I did all of this, I was mostly just doing a lot of educated guessing and stabbing in the dark. I came to deeply appreciate my experience of having worked on large C++ code bases, it really helped fill in a lot of the blanks simply because I could make educated guesses along the way.
So, what does retrieve_workload do? Well, first things it does is check if there already exists a workload on the command buffer and then return that (another struct member filled in), if there isn’t one already, it’ll make a new one by filling in some information into a struct on the stack and then passing that into what I called allocate_workload. That function is mercifully simple, essentially it does this:
puVar2 = (AdrenoWorkload *)calloc(1,0x388);
if (puVar2 != (AdrenoWorkload *)0x0)
{
puVar2->field18_0x54 = uVar3;
puVar2->vtable = &PTR___cxa_pure_virtual_002aed00;
*(undefined8 *)&puVar2->field_0x8 = 0x100000000;
// A lot more initialization code
// ...
return puVar2;
}
So, from this I learned more things: An AdrenoWorkload (my name) object is 0x388 bytes in size and is a C++ class with vtable. You can see the various constructors run, each filling in more pieces of the instance and updating the vtable. It mostly fills all members with zeroes, which meant I didn’t get too much information about the internal layout yet. But a foothold is a foothold and armed with the size and knowing it was a C++ class, I went back up the stack to see what else retrieve_workload does. No surprises here, but essentially this function will do some more initialization while looking at various command buffer states. In real time this took a lot of back and forth and I had also started to sink my teeth into the vkCreateRenderPass() and vkCreateFramebuffer functions as well. Having unraveled things up to this point, I was able to take advantage of Ghidra’s reference utility to find other places where various members of the workload struct are used. I made extensive use of this to fill in the bigger picture of how the pieces were connected together. Turns out, retrieve_workload spends a lot of time looking at the render pass and subpass state and using that to fill in its internal state. This makes sense because Adreno GPUs are tilers and the whole subpass business mostly exists to improve performance on tilers. After doing all of this, the driver ends up inserting the workload into a linked list of workloads and this is what vkEndCommandBuffer() iterates over.
workload_entry = (AdrenoWorkloadEntry *)calloc(1,0x10);
if (workload_entry == (AdrenoWorkloadEntry *)0x0)
{
// Error handling
}
else
{
command_buffer->workload = workload;
workload_entry->item = workload;
workload_entry->prev = (AdrenoWorkloadEntry *)0x0;
if (command_buffer->workload_tail == (AdrenoWorkloadEntry *)0x0)
{
command_buffer->workload_tail = workload_entry;
}
else
{
command_buffer->workload_head->prev = workload_entry;
}
command_buffer->workload_head = workload_entry;
command_buffer->workload_count = command_buffer->workload_count + 1;
}
This linked list gave a lot of headache at first, but I think it’s just this weird because it’s something like C++s std::list. Instead of being an intrusive linked list, there is a header object that’s the actual linked list item entry that I called AdrenoWorkloadEntry. Essentially it points to the actual item and also contains the prev pointer.
Intermission: Drawing without crashing, or output
Suspicion confirmed, the workload is very interesting, because whatever is in it will eventually lead to a crash. Having filled in a bunch of blanks, I figured it was time to look at the rest of the stack frames. Mind you, my goal was not to completely reverse engineer the driver, I just wanted to find out what was causing my crash. I figured I might have enough pieces filled in at this point to at least narrow it down further. I was partially right, I discovered a debug log function much closer to the crash site. This debug log suggested it was doing some sort of store operation. Or at least it was logging something about stores 2 stack frames away from the segfaulting function. Armed with that knowledge, I decided to just try setting our render pass store op to DONT_CARE and would you believe it: It stopped crashing! Of course, there was no output because I told the driver that I couldn’t care less about it, but it was no longer crashing. This allowed me to finally run this under RenderDoc and confirm that everything looked as expected from the command stream side. Stepping through the commands captured by RenderDoc also allowed me to see the results on the phone’s screen itself and that was not crashing either.
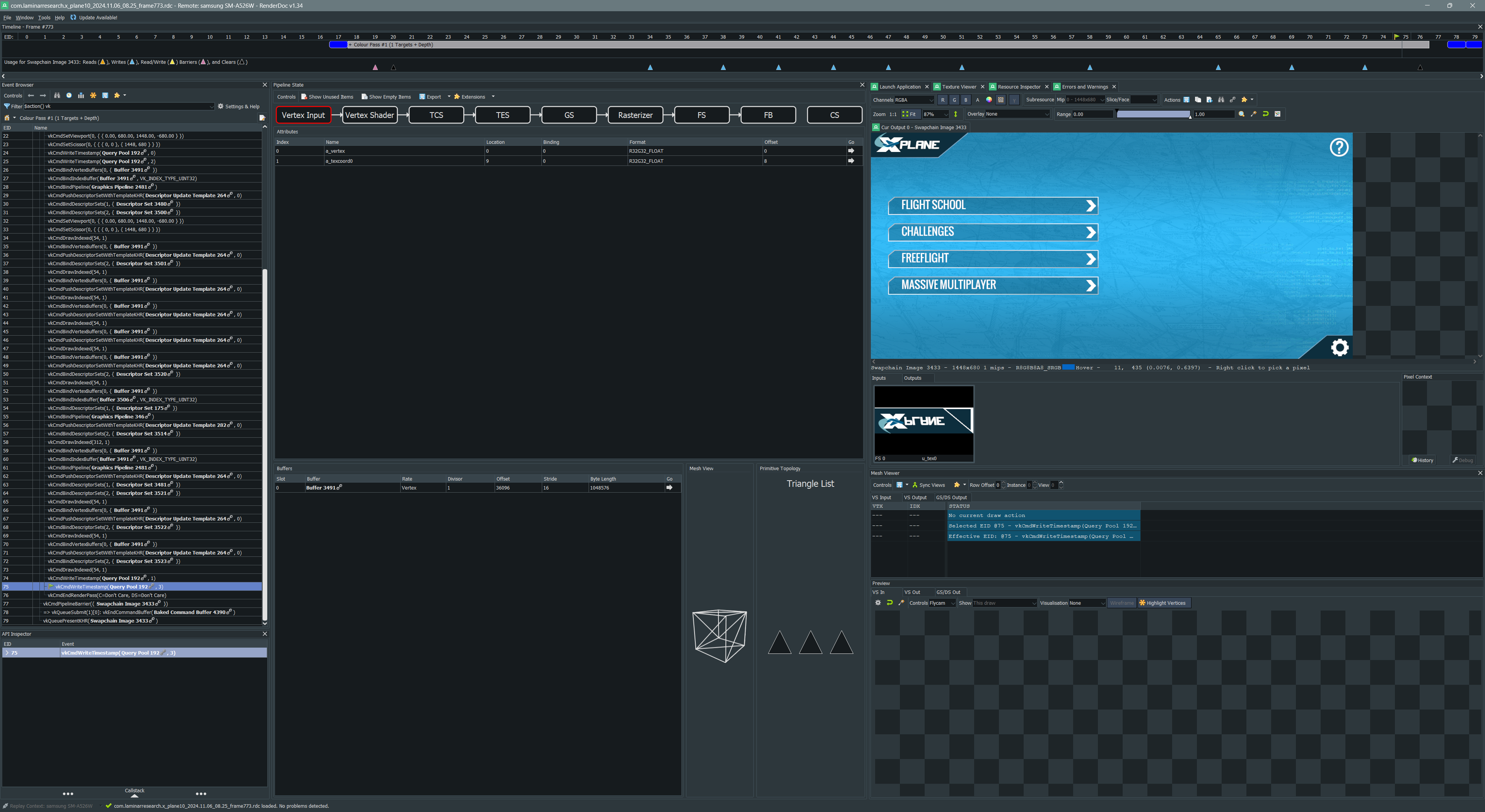
Of course, once I enabled the store again, it all went back to crashing. But all of this gave me the confidence that I was on the right track and that our command data isn’t bad, because RenderDoc can replay it.
Putting it all to bed
And then, all I did was go back to everything around framebuffers, render passes and draw calls and just filled in as much of the struct member data as I could. Interestingly, VkCommandBuffer_T is just a wrapper pointing to an internal object but this isn’t the case for other Vulkan objects. VkRenderPass_T for example is the real driver object directly. I kept getting stuck at various places, but context switching around and filling in other pieces around the structs I was interesting in, helped me go back to various other pieces and unravel things bit by bit. I don’t want to give the impression that I nailed all of this on the first try, I ended up going back to various functions that I had thought I had figured out and then had to redo large parts of, after learning some new piece of information. My strategy involved just naming interesting struct members things like what_is_this_thing and who_are_you and then work backwards from there, seeing where they get consumed and also written. I could then go back and give things proper names and keep filing in the puzzle pieces. For example one function that I got very wrong initially was vkCreateRenderPass. In and of itself an easy function, especially if you know exactly what all the input parameters are. But I ended up getting it severely wrong. My first assumption was that a call to calloc() early on was already the allocation of the render pass object itself. This lead me to assuming the struct was the wrong size, not to mention also making the following code really confusing.
Eventually I was able to put the puzzle together. Really helpful here was that Vulkan allows passing in custom allocation functions, so I was able to use that as a foothold to see where the driver allocates various objects. I was also able to skip large sections of the code and mark struct members as not interesting because they were dealing with the multiview attachment and fragment density map extensions. This was pretty easy to do because I could see the driver walk the pNext extension structure chain and then I could just skip anything it did as a result of that, although I did annotate the render pass struct with all of this just so I knew what was where. One thing that I discovered as a result of this is that the Adreno driver appears to deeply prefer no allocation callbacks. Without allocation callbacks and given render passes that cover no more than 5 attachments, the driver seems to just use scratch memory in the render pass object itself to store various states. Otherwise, the driver will allocate additional objects for all of this. A good part of understanding the code was solving these puzzle pieces and being able to collapse large chunks of the control flow that was just dealing with the various allocation strategies. My guess is that 5 is the magic number that covers the majority of g-buffer implementations and helps reduce memory allocations and cache misses while also not making the objects excessively expensive for render passes that don’t need any of this.
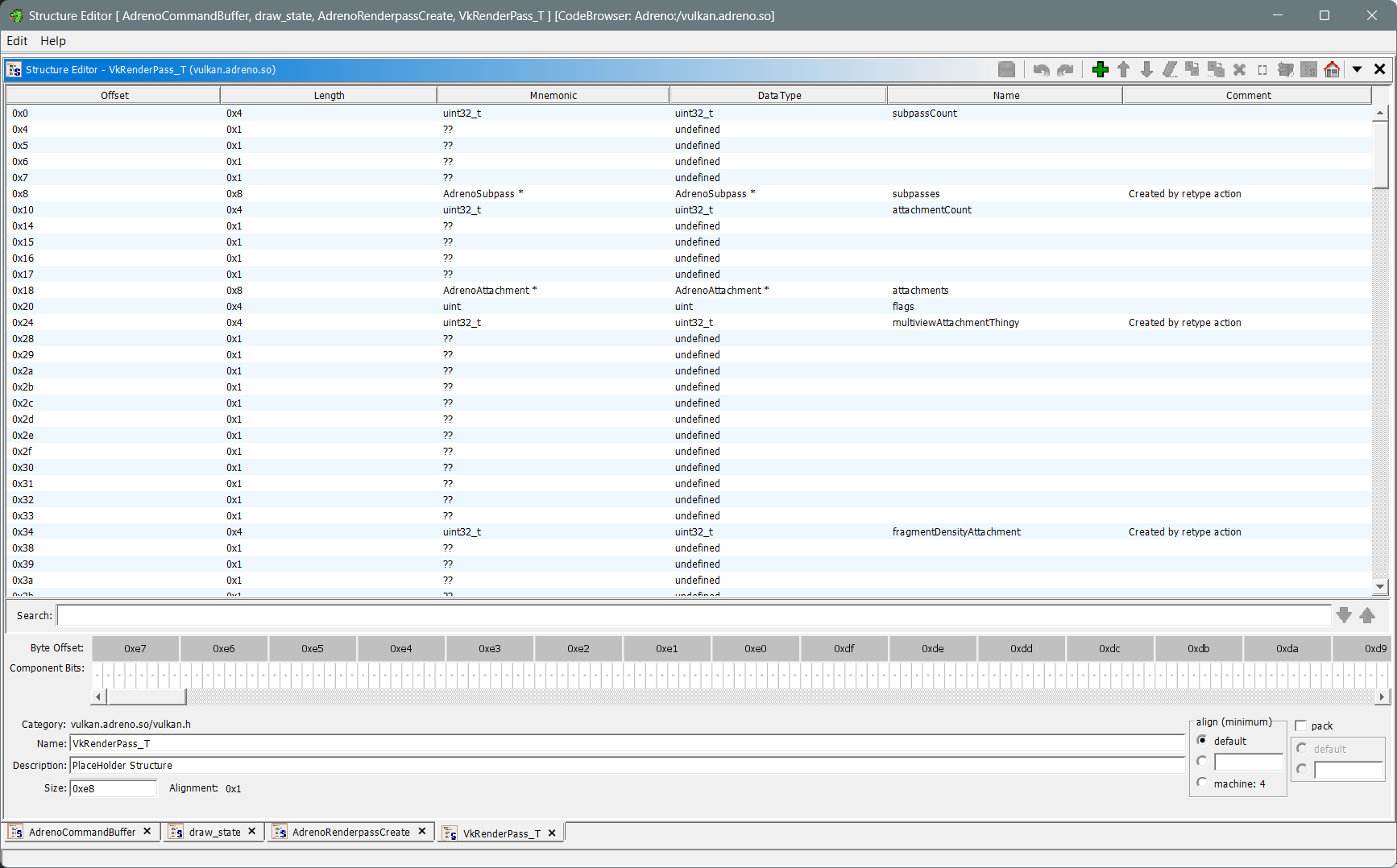
And then, I found the final piece of the puzzle in the framebuffer: At this point I had a pretty decent idea that the crashing code was finalizing subpasses and their interactions with attachments. Being a Desktop code base, we use only one subpass and no dependencies on our render passes, so I knew I could skip some of the code. Although of course, I did try to mess around with subpasses and dependencies just to see if it changed the crash behaviour. I did this a lot, as I learned more things, I went back into our code to see if I could change things around to alter the behaviour of the crash and bisect this from multiple angles. Needless to say, this was never resulting in anything but it helped steer me in the right direction on the reverse engineering side. This where things finally fell together: vkCreateFramebuffer takes a render pass as input to describe how the framebuffer will be accessed. My assumption is that this is to allow the driver to optimize the framebuffer layout in some way, but crucially for X-Plane, we always just created a temporary render pass and then threw it away after framebuffer creation. However, looking at the vkCreateFramebuffer() code, I noticed that the Adreno driver stores the pointer to that render pass in the framebuffer object and even more importantly: That was the pointer it was de-referencing when doing the final pass over the workloads. Boom!
Intentionally leaking the temporary render pass and it all was happy. No more crashing and I could see the main menu on the phone! And… That’s it. I don’t know why the driver looks at the render pass. After all, my goal was to fix whatever was crashing X-Plane, not to figure out how Qualcomms driver works. Of course I cleaned up the leak and made the fix production ready, but that’s kinda the end of it. I asked on the Khronos Slack if it was the driver or me who was in the wrong here, and Baldur of RenderDoc fame pointed at the relevant spec text:
A VkRenderPass or VkPipelineLayout object passed as a parameter to create another object is not further accessed by that object after the duration of the command it is passed into.
So an Adreno driver bug. Not that it really matters since the driver will most likely not see updates, so the workaround on our end will stay around. But at least I felt vindicated about my code. Disappointing ending, I know. But it was an incredibly fun puzzle to work on and I can’t express just how lucky I feel being paid doing cool things like this. I learned a lot in the process and had a ton of fun, what more can I ask for?
The last question of course is: Could ASAN have found this faster? The answer is no. ASAN does detect something, but it unhelpfully says that it can’t provide any context for what it found. The temporary render pass was already destroyed so long ago, the history buffer of ASAN was no longer keeping track of it.